Git
Posted at 07:00 on 23 September 2010
Some people say that Git is easy to learn.
That is like saying that War and Peace is on the same intellectual level as The Suite Life of Zack and Cody.
I don’t know about you, but whenever I hear anyone promoting any set of arcane command-line instructions as “easy to learn,” I wonder what on earth they’ve been smoking. While command line instructions can sometimes be easier to learn than their GUI counterparts, any technology for which that is true is generally either esoteric, immature, or badly designed, and besides, command line instructions are not a good marketing strategy.
Here’s what “easy to learn” means.
- An intuitive, uncluttered, and self-explanatory graphical user interface.
- For at least 80% of what I need to do, it’s immediately obvious how to do it, and even when it’s not, I can quickly learn by experimentation and educated guesses, with only minimal reference to the manual.
- The documentation itself is clearly written, easy to understand, uses a de facto standard terminology where one exists, and does not overwhelm me with irrelevant details.
- No gotchas or complex workarounds, and above all, no Nasty Surprises.
As far as source control usability and learning curve goes, TortoiseHg is pretty much the gold standard these days against which I judge all other SCMs. Almost all of them fall short of it, to a greater or lesser degree, on at least one of the above counts.
One thing I learned very early on with Git is that the manual is not an optional extra. Experimentation and educated guesses simply don’t work, otherwise you’ll end up in trouble. And don’t be fooled into thinking that TortoiseGit is a practical substitute: it isn’t. You still have to Read The Manual.
Unfortunately, the fact that the manual is somewhat closer to War and Peace than Zack and Cody in terms of understandability doesn’t help. The man page for git log extends to more than 1,200 lines, as compared to a mere sixty for hg log, and 69 for svn log, for example, and it is all stuffed full of Git-specific low-level sounding jargon such as “remote refs,” which I’ve never, ever heard used in the context of any other source control system anywhere. Not Mercurial, not Subversion, not CVS, not Team Foundation Server, not even Visual SourceSafe.
Fortunately, there are books, such as Scott Chacon’s Pro Git, which make things somewhat more transparent, but unfortunately, they are still too command-line centric and say little if anything about visual tooling.
The task at hand was branching and merging. I learned all about this with a mere half hour’s experimentation and educated guesses with TortoiseHg, about eighteen months ago. It’s almost trivially easy. You simply right-click on the revision off which you wish to base your branch and choose “Update.”
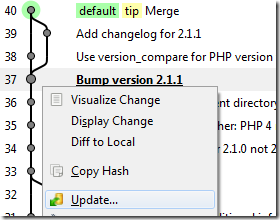
Then you commit, and voilà, there’s your branch, right alongside the old one.
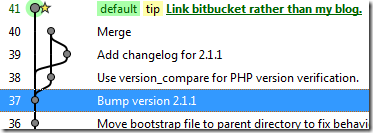
Nice and intuitive, just as you’d expect a DAG-based source control system to behave. Reboot your computer and come back in six months’ time and it’ll still be there.

What about git? Well, now I understand why the Git mascot is a hundred-foot tall branch-eating monster. It turned out to be surprisingly prophetic.
In Mercurial, it’s a good idea to treat branches as essentially anonymous, since Mercurial’s concept of named branches is not all that useful: tags, bookmarks or separate repository clones are more appropriate, depending on what you are trying to achieve. Your history is a directed acyclic graph, after all. But a key feature of every source control system on the face of the planet is that your history is pretty much immutable unless you explicitly do things like rebasing or stripping revisions. I assumed, therefore, that in Git, branch names are also an optional extra.
So I click “Show Log” on the TortoiseGit menu, and right-click on the revision I want to use as a base:
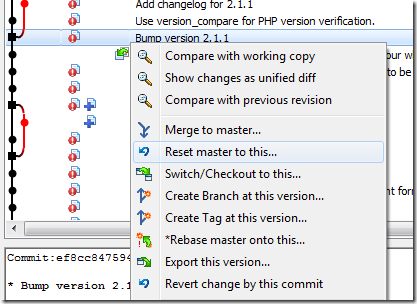
Hmmm. Which option here? There are a few options for creating a branch and so on, but they all expect you to name it. I just want to create a quick anonymous branch for the time being, and give it a name later if need be — after all, that is how a DAG is supposed to behave, isn’t it? Isn’t it?
A promising candidate for this seems to be “Reset master to this.” So I give it a shot.
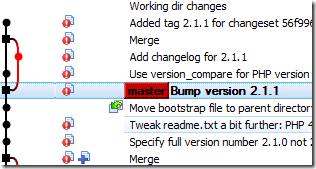
Looks like I’m on the right lines. I make a change, commit, and then…
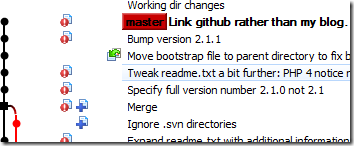
Ouch! My old branch has gone missing. Fortunately, I notice a checkbox at the bottom. “All Branches.” It’s unchecked, so I check it, and my branch reappears:
That’s a relief, I’ve got it back. Obviously I’m heading in the right direction here. I close down TortoiseGit and go off and do something else.
But.
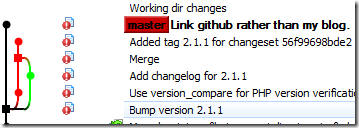
I’m soon to discover that TortoiseGit has been leading me a merry dance. A bit later, I come back to do a bit more work, start up TortoiseGit “Show Log” again, and this time I see this:
What?…?! Where’s my old branch gone?!
I try various combinations of the boxes at the bottom labelled “Show Whole Project” and “All Branches” and “Hide Unrelated Change Paths.” All to no avail. I even drop down to a command prompt and type in git log. I type git help log and hunt in vain for an option that will let me get my old branch back. But there’s no sign of it anywhere. It’s disappeared. Vanished into thin air. Been eaten by the Git Monster. Gone.
This is Not A Good Sign. I don’t see how I can possibly recommend a source control system to Subversion users, source control newbies, DVCS naysayers, and my boss, when it makes bits of your project’s history vanish without trace when you don’t expect it to.
A bit of googling eventually leads me to this:
You can reset the state of any branch to an earlier commit at any time with
$ git reset --hard v2.5This will remove all later commits from this branch and reset the working tree to the state it had when the given commit was made. If this branch is the only branch containing the later commits, those later changes will be lost. Don’t use “git reset” on a publicly-visible branch that other developers pull from, as git will be confused by history that disappears in this way.
In other words, I’ve messed up. git reset is not the equivalent of hg update, but of hg strip — except that it isn’t, because if TortoiseGit is anything to go by, rather than doing it immediately, it waits till you’ve gone off for a cup of tea then does it behind your back. Clearly, experimentation and educated guesses are dangerous with git. In fact I’m not even sure if git actually has an equivalent of hg update. Branches have to have names, and if they don’t, then Bad Things Happen.
So, is there any way to get my branch back? I do another quick Google search only to find that things are worse than I thought:
I need to recover two Git branches that I somehow deleted during a push.
Sheesh. You mean to say you can actually delete a part of your project’s history in the central repository simply by pushing to it?!
Apparently all is not lost though. The lost commits are still there, but just inaccessible, and it is possible to recover them by typing in commands bearing a vague resemblance to transmission line noise at the command prompt. It sounds like lost commits are a problem that git users are running up against all the time, and there are plenty of other ways that this can sneak up on you unawares, not just naively assuming that git behaves in a similar way to Mercurial:
More traditional version control systems don’t give you as much power as Git by any stretch of the mind. They are like taking a walk in the woods with your parents, at age 14.
You’re probably gonna see and do neat stuff, but you sure ain’t gonna get lost or anything.
Using Git on the other hand is more akin to being handed a cool motocross to go play alone in the woods… Also at age 14.
We all know what’s bound to happen, right?
You’ll smash into a tree.
The source control equivalent to slamming into a tree is losing commits…
This sounds like a support nightmare. Persuade a team of thirty average enterprise developers to adopt git, and you can forget ever getting any code written for helping them deal with their problems every time they mess up. And I thought Subversion was bad with its cranky .svn directories!
Of course I’m sure it all makes sense once you manage to get your head round it, but it all seems too volatile and disconcerting for my liking, and it leaves me wondering what else is lurking in there. I like to be in control of my source. It is called source control, after all.
I’m sure that git has its place, and it would appeal to a certain kind of person who likes programming for programming’s sake and relishes the prospect of mastering really complex tools. As for Github, it’s nice and all that, but when it boils down to it, the only real reason why I personally would want to use it rather than, say, Bitbucket or Google Code, would be to impress the kind of people who use Github.
But that’s not the point of programming in the first place. When you’re programming, the most important people in the equation are your end users, and that’s something that open source developers often lose sight of. With that in mind, the most important thing you want from your tools is that they do what they’re supposed to do, but otherwise keep out of the way, and let you get on with the task at hand. For that reason, I think I’m going to stick with Mercurial and Bitbucket.