Why merges can (and should) be automated
Posted at 07:00 on 04 April 2011
Long time Mercurial users will no doubt appreciate the new merge and conflict resolution dialogs in TortoiseHg 2.0. When you have some conflicting files, rather than making you go through them one at a time with no idea how many more there are to handle, you are given a list of them with options to help you merge them.
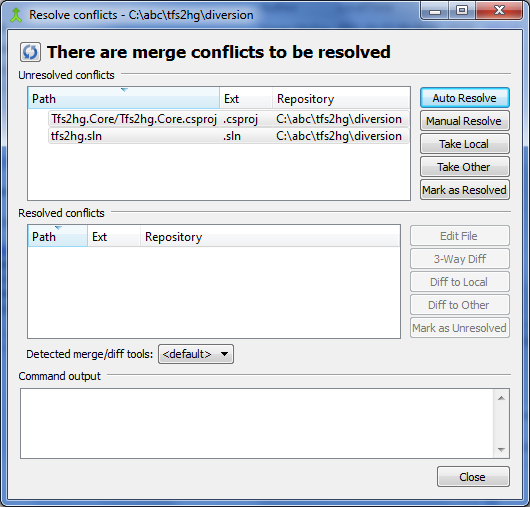
However, there is one feature of this dialog that will no doubt raise an eyebrow or two. Whenever a file has been modified on both sides of the merge, it reports it as a conflict, even if the modifications were to completely different parts of the file. What is going on here? Has Mercurial suddenly forgotten how to merge? Is it turning into Team Foundation Server? Whatever next, read-only files and baseless merges?
Actually, no it hasn’t. That was my reaction when I first tried out the development version of TortoiseHg 2.0 last summer, so I rolled up my sleeves and coded up an option to restore the traditional behaviour:
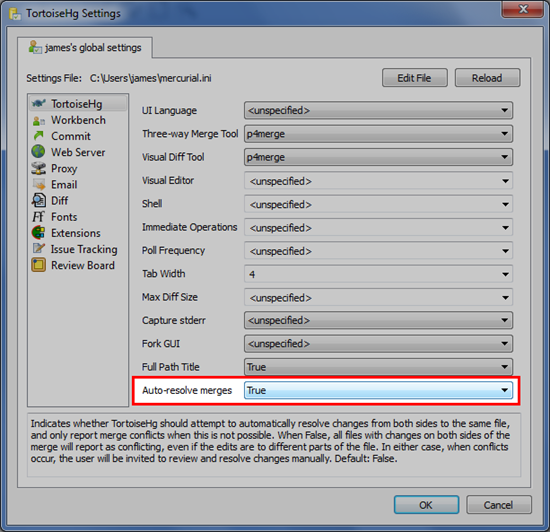
When you merge, you can also choose on a case by case basis between automatic and manual file resolution:

So why does it work this way now? In my discussions on the TortoiseHg mailing list, Steve Borho, the lead developer of TortoiseHg, pointed out that there’s a lot of hallway usability testing behind it:
I'll allow that long-time Mercurial users may find this limiting, so I've assumed that we'll eventually add a back door to revert to default Mercurial behavior. But I have heard from many new users over the years that this is the one part of the Mercurial interface that is unsettling, having kdiff3 thrown at them at seemingly random occasions, so I want the internal:fail approach to be the initial default.
André Sintzoff concurred:
I agree with you. Most of the new users I know are somehow disturbed by the "old" merge behaviour.
When I show them the "new" behaviour, they are enthusiast.
They had a valid point. This is something I’d forgotten about myself.
Inexperienced developers are usually terrified of merging. When you’re combining two people’s changes together, you need to know and understand not only the changes themselves, but the context as well. To delegate the entire process to some unknown computer algorithms sounds reckless and dangerous. This was one of the first things I found intimidating about svn update when I first started using source control in a team context in the first place.
Yet in practice, fully automated merging works remarkably well. When you run svn update or hg merge, more often than not, it all goes very smoothly -- in fact, much more so than attempting to merge everything manually. Why should this be?
1. In the overwhelming majority of cases, the default option is the correct one.
Next time you do a merge, turn off automatic conflict resolution and use a three-way tool such as Perforce Merge. I particularly like Perforce Merge because it shows you exactly what’s going on. At the top, you have the two sides of the merge on either side of the original version, so you can tell whether something was added on the left hand side or whether it was deleted on the right hand side:
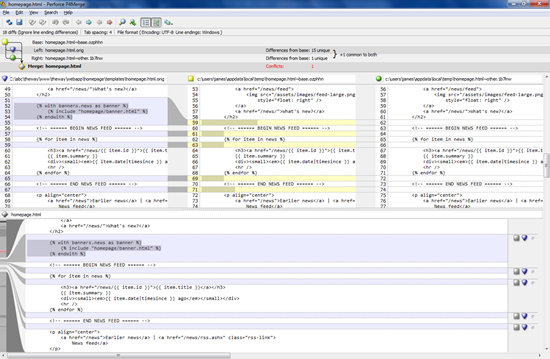
In the most basic case, automated merge tools assume that if a change was made to one side of the merge, but there is no corresponding change on the other side, that change should be included in the final result. That’s what shows up in the bottom pane. On the other hand, if two people have edited the same part of the file, it shows up as a merge conflict and you have to resolve it manually.
Now here’s the key. Once you’ve carried out a few manual merges, you soon realise that with non-conflicting text differences, you almost never choose anything other than this default option. It becomes evident that working your way manually through a string of differences where you only ever choose the default is largely a waste of time.
2. Manual merges increase the risk of human error.
Having said that, automated merges don’t always get it right, and you do sometimes need to be aware of the context on each side. But -- and it is a big but -- manual merges fare no better.
Here’s a simple example where both automatic and manual merges are liable to give the wrong result. Let’s say that two developers, Alice and Bob, both make an identical change to a source file on their respective branches -- for example, throwing an exception when something can’t be found. Then, Bob commits a subsequent change which backs it out. Should the new code be included in the merge or not?
Changed ------
/ \
Original ???????
\ /
Changed - Original
Mercurial and Git both take the line that because Bob undid the change, it should be as if he had never made it in the first place -- a feature called “implicit undo” -- and therefore, the change should be included in the merge. But that is not necessarily what you want. An ideal version control tool would report this as a conflict, but what happens then?
Here’s what it might look like in your merge tool:
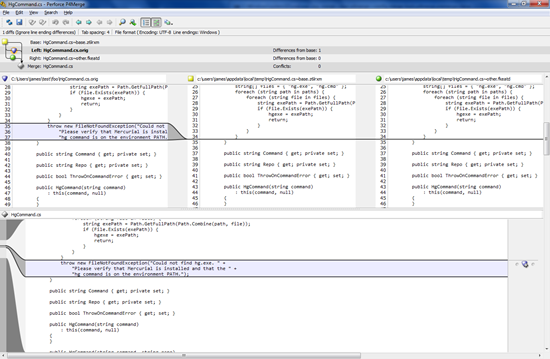
There is no indication whatsoever that as well as being added on the left hand side, that exception was also added on the right hand side and then deleted again. Because your manual merge is a naive three-way merge, with no awareness of history, it also gives you implicit undo, and unless you are particularly on the ball and aware that this change was made then undone in the first place, you won’t pick up on it.
But if you’ve just worked your way through a dozen or more diffs where you’ve chosen the default option every time, the chances are that your eyes will be glazing over, you won’t be on the ball, and you’ll miss it. And therein lies the rub: as well as being slow, manual merge resolution increases the risk of human error.
Another problem with manual merge resolution is that it frequently presents you with diffs that are pretty confusing and overwhelming. Visual Studio .sln files are a particular pain to work with in this respect, since you are dealing with lines and lines of GUIDs that blur into each other. Very often, the only difference between the two sides is that stuff has been moved around. In cases such as these, it can be almost impossible to carry out a manual merge effectively, whereas an automated merge will work out fine. Long lines just compound the problem.
So there’s your trade-off. An automated merge, which may or may not be correct due to ignorance of context. Or a manual merge, which may or may not be correct due to human error and lack of clarity of both context and content. And is several orders of magnitude slower into the bargain.
3. Semantic resolution is easier dealt with by compiling and testing anyway.
The upshot of this is that merging is actually a two-pass process, regardless of how you do it. The mechanical operation of combining your changes is not the be-all and the end-all, but only the first step. Once you’re done with it, you will need to test your merge and fix up any problems. But this isn’t a big deal -- it’s the kind of thing you’re doing all the time in normal coding anyway.
Besides, manual resolution only gives you a narrow view of what you’re doing. It’s only when you compile and test that you really see how the two sides of the merge fit together and get a feel for how to deal with the context and intent of the two sides of the merge.
Most problems with merges show up when you attempt to compile your code. In these cases, it’s merely a case of fixing them up -- clearing up ambiguous references, checking renames and so on. If you have good test coverage (and you should have good test coverage), your unit tests will pick up the majority of other problems, though you do need to be aware that incorrect merges may have an impact on your tests too. And while some problems may slip through the net, they generally are pretty insignificant in number and scope compared to bugs that creep in through normal, everyday coding.
Fully manual merge resolution is helpful for new users because it eases them gradually into the apparently scary world of branching and merging. But once you are used to it, it becomes apparent that there is little or no benefit to the all-manual approach. While you may feel more in charge of the process while you’re carrying it out, this is largely illusory and a waste of time, somewhat akin to premature optimisation. Provided that your tooling has decent automatic merge support -- and Mercurial certainly does have decent automatic merge support -- there’s every reason to make the most of it.